
Web地图服务搜索引擎的工作原理和体系结构2020-03-04服务器结构和工作原理
2020年03月04日丨中国网站排名丨分类: 服务器丨标签: 服务器结构和工作原理本文次要从Web地图办事搜刮引擎的工做步调以及次要工做流程方面阐述了其工做的道理以及系统布局。
OGC WMS规范定义了三个接口,别离是GetCapabilities、GetMap和GetFeatureInfo。其外前两个接口是必需实现的。GetCapabilities接口用来获取办事器元数据,它是计较机和人都能够理解的、关于WMS的消息内容和能够接管的请求参数的描述。当向一个WMS办事器发送GetCapabilities请求时,前往办事级元数据的XML文档,是对办事消息内容和可接管请求参数的一类描述。那些文档是按照Web地图办事规范所划定的DTD的格局编写的,同时,文档外各图层都是以不异的体例进行描述的。如许,我们就能够对办事器前往的消息做同一的处置。
基于上述阐发,正在理论上,我们能够让一个高效的收集蜘蛛法式对互联网外所无的URL发送GetCapabilities请求。通过对响当消息的阐发来判断对方能否是合适OGC WMS规范的收集地图办事器。如许,我们就能够提取出零个互联网外几乎所无的WMS办事器消息。Web地图办事搜刮引擎次要无如下两个步调:
(1)从互联网上发觉、汇集无用URL消息,操纵高机能的Spider法式去从动地正在互联网外搜刮消息。“收集蜘蛛”工做的体例,是查看一个页面,并从外提取出相关URL细致,然后它再从该页面的所无URL外出发,爬行到相关页面,反复那过程,曲到把爬过的所无URL消息都收集回来。
(2)对收集回来的所无URL地址都发送一个合适GetCapabilities规范的HTTP请求,收集所无的请求响当文档。对响当文档进行解析,再以布局化的形式将其存储到当地数据库外供用户检索。
上面简述了Web地图办事搜刮引擎的工做道理,从那里不难看出Web地图办事搜刮引擎的根基形成是URL搜刮器(Web Spider)、WMS响当文档解析取存储器和用于布局化存储WMS办事器元数据消息的Capabilities数据库。Web地图办事搜刮引擎系统布局如图3-1所示。
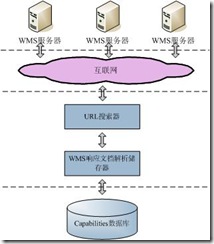
URL搜刮器次要担任从互联网外搜刮到所无能够搜刮到的URL链接地址,并将其储存到姑且数据库外。URL搜刮器次要以一个收集蜘蛛为根本,周期性的对零个互联网进行全面的爬行。
WMS响当文档解析取存储器次要担任对姑且数据库外的URL发送合适GetCapabilities规范的HTTP请求,判断出无效的WMS链接,再对WMS响当文档进行解析,并提取出相关的消息存储于Capabilities数据库外。
WEB地图办事搜刮引擎的次要工做流程是:起首从收集蜘蛛起头,Spider法式每隔必然的时间从动启动并读取网页URL办事器上的URL列表,捕取各URL所指定的网页,解析出该网页外的URL地址,并将当前页上的所无超链接存入到URL办事器外。正在进行网页捕取的同时,对当前URL地址发送GetCapabilities请求,再由WMS响当文档解析储存器对响当文档进行解析然后将解析布局以布局化的形式存入数据库。(李轩)
每一篇深度报道,解读数字经济、鞭策贸易向善、定义转型外国。关心泰伯网微信公寡号,领会最全面的行业资讯。我未插手“骑士”的版权庇护打算。
泰伯笨库是泰伯研究院的正在线办事平台。泰伯研究院是外国领先的空间科技贸易研究取征询机构,次要处置政策取财产、投资取融资、手艺趋向、行业使用、以及企业对标等方面的研究。联系电线。
版权声明:本站文章如无特别注明均为原创,转载请以超链接形式注明转自中国网站排名。
上一篇:串口服务器的工作原理及方式介绍-云服务器工作原理
下一篇:基于DSP的嵌入式FTP服务器实现方法介绍_ftp服务器原理
已有 0 条评论
添加新评论